机器与人类视觉能力的差别
论视觉理解和像素理解
机器与人类视觉能力的差距
很多人以为人工智能就快实现了,往往是因为他们混淆了“识别”和“理解”。现在所谓的“人工智能”都是在做识别:语音识别,图像识别,而真正的智能是需要理解能力的。我们离理解有多远呢?恐怕真正的工作根本就没开始。
很长时间以来,我都在思索理解与识别的差别。理解与识别是很不一样的,却总是被人混为一谈。我深刻的明白理解的重要性,可是我发现很少有其他人知道“理解”是什么。AI 领域因为混淆了识别和理解,一直以来处于混沌之中。
最近因为图像识别等领域有了比较大的进展,人们对 AI 产生了很多科幻似的,盲目的信心,出现了自 1980 年代以来最大的一次“AI 热”。很多人以为 AI 真的要实现了,被各大公司鼓吹的“黑科技”冲昏了头脑,却看不到现有的 AI 方法与人类智能之间的巨大鸿沟。所以下面我想介绍一下我所领悟到的机器和人类在视觉能力方面的差距,希望一些人看到之后,能够再次拥有冷静的头脑。
“图像识别”和“视觉理解”的差别
对于视觉,AI 领域混淆了“图像识别”和“视觉理解”。现在热门的所谓 “AI” 都是“图像识别”,而动物的视觉系统具有强大的“视觉理解”。视觉理解和图像识别有着本质的不同。
深度学习视觉模型(CNN一类的)只是从大量数据拟合出从“像素=>名字”的函数。它也许能从一堆像素猜出图中物体的“名字”,但它却不知道那个物体“是什么”,无法对物体进行操作。注意我是特意使用了“猜”这个字,因为它真的是在猜,而不像人一样准确的知道。
“图像识别”跟“语音识别”处于同样的级别,停留在语法(字面)层面,而没有接触到“语义”。语音识别是“语音=>文字”的转换,而图像识别则是“图像=>文字”的转换。两者都输出文字,而“文字”跟“理解”处于两个不同的层面。文字是表面的符号,你得理解了它才会有意义。
怎样才算是“理解了物体”呢?至少,你得知道它是什么形状的,有哪些组成部分,各部分的位置和边界在哪里,大概是什么材料做成的,有什么性质。这样你才能有效的对它采取行动,达到需要的效果。否则这个物体只是一个方框上面加个标签,不能精确地进行判断和操作。
想想面对各种日常事物的时候,你的脑子里出现的是它们的名字吗?比如你拿起刀准备切水果,旁边没有人跟你说话,你的脑子里出现了“刀”这个字吗?一般是没有的。你的脑子里出现的不是名字,而是“常识”。常识不是文字,而是一种抽象而具体的数据。
你知道这是一把刀,可是你的头脑提取的不是“刀”这个字,而是刀“是什么”。你的视觉系统告诉你它的结构是什么样的。你知道它是金属做的,你看到刀尖,刀刃,刀把,它也许是折叠的。经验告诉你,刀刃是锋利的可以切东西的部分,碰到可能会受伤,刀把是可以拿的地方。如果刀是折起来的,你得先把它翻开,那么你从哪一头动手才能把它翻开,它的轴在哪里?
你顺利拿起刀,开始切水果。可是你的头脑里仍然没有出现“刀”这个字,也没有“刀刃”,“刀把”之类的词。在切水果的同时,你大脑的“语言中心”可能在哼一首最近喜欢的歌词,它跟刀没有任何关系。语言只是与其他人沟通的时候需要的工具,自己做事的时候我们并不需要语言。完成切水果的动作,你需要的是由视觉产生的对物体结构的理解,而不是语言。
你不需要知道一个物品叫什么名字就能正确使用它。同样的,光是知道一个物品的名字,并不能帮助你使用它。看到一个物体,如果脑子里首先出现的是它的名字,那么你肯定是很愚钝的人,无法料理自己的生活。现在的“机器视觉”基本就是那样的。机器也许能得出图片上物体的名字,却不知道它是什么,无法操作它。
试想一下,一个不能理解物体结构的机器人,它只会使用图像识别技术,在你的头上识别出一个个的区域,标注为“额头”,“头发”,“耳朵”…… 你敢让它给你理发吗?
这就是我所谓的“视觉理解”与“图像识别”的差别。你会意识到,这种差别是巨大的。
视觉识别不能缺少理解
如果我们降低标准,只要求识别出物体的名字,那么以像素为基础的图像识别,比如卷积神经网络(CNN),也是没法像人一样准确识别物体的。人识别物体并不是像神经网络那样的“拍照,识别”两节拍动作,而是一个动态的,连续的过程:观察,理解,观察,理解,观察,理解……
感官接受信息,中间穿插着理解,理解反过来又控制着观察的方向和顺序。理解穿插在了识别物体的过程中,“观察/理解”成为不可分割的整体。人看到物体的一部分,理解了那是什么,然后继续观察它周围是什么,反复这个过程,最后才判断出物体是什么。
这个“观察/理解”的过程发生的如此之快,眨眼间就完成了,以至于很多人都没察觉到其中“理解成分”的存在。所以我们现在放慢这个过程,来一个慢镜头特写,看看到底发生了什么。假设你从来没见过下面这个东西,你知道它是什么吗?

一个从没见过这东西的人,也会知道这是个“车”。为什么呢?因为它有轮子。为什么你知道那是轮子呢?仔细一想,因为它是圆的,中间有轴,所以好像能在地面上滚动。为什么你知道那是“轴”呢?我就不继续折腾你了,自己想一下吧。所有这些分析都是“视觉理解”所产生的,而这些理解依赖于你一生积累的经验,也就是我所谓的“常识”。
其实为了识别这个东西,你并不需要分析这么多。你之所以做这些分析,是因为另一个人问你“你怎么知道的?” 人识别物体靠的是所谓“直觉”。一看到这个图片,你的脑子里自然产生了一个 3D 模型。一瞬间之后,你意识到这个模型符合“车”的机械运动原理,因为你以前看见过汽车,火车,拖拉机…… 你的脑子里浮现出这东西可能的运动镜头,你仿佛看到它随着轮子在动。你甚至看到其中一个轮子压到岩石,随着连杆抬了起来,而整个车仍然保持平衡,没有反倒,所以这车也许能对付崎岖的野外环境。
这里有一个容易忽视的要点,那就是轮子的轴必须和车体连在一起。如果轮子跟车体没有连接,或者位置不对,看起来无法带着车体一起运动,人都是知道的。这种轮轴与车身的连接关系,属于一种叫“拓扑”(topology)的概念。
拓扑学是一门难度挺高的数学分支,但人似乎天生就理解某些浅显的拓扑概念。实际上似乎高等动物都或多或少理解一些拓扑概念,它们一看就知道哪些东西是连在一起的,哪些是分开的。捕猎的动物都知道,猎物的尾巴是跟它们身体连在一起的,所以咬住它们的尾巴就能抓住它们。
拓扑学还有一个重要的概念,那就是“洞”。聪明一点的动物基本上都理解“洞”的概念。很显然老鼠,兔子等穴居动物必须理解洞是什么。它们的天敌,猫科动物等,也理解洞是什么。如果我拿一个纸箱给我的猫玩,我在上面挖一个洞,等他钻进去,他是不会进去的。我必须在上面挖两个洞,他才会进去。为什么呢?因为他知道,要是箱子上面只有一个洞,要是他进去之后洞被堵上,他就出不来了!
机器如何才能理解洞这个概念呢?它如何理解“连续”?
总之,人看到物体,他看到的是一个 3D 模型,他理解其中的拓扑关系和几何性质,所以一个人遇到前所未见的物体,他也能知道它大概是什么,推断出如何使用它。理解使得人可以非常准确地识别物体。没有理解能力的机器是做不到这一点的。
人的视觉系统与机器的差别
人的眼睛与摄像头有着本质的差异。眼睛的视网膜中央非常小的一块区域叫做“fovea”,里面有密度非常高的感光细胞,而其它部分感光细胞少很多,是模糊的。可是眼睛是会转动的,它被脑神经控制,敏捷地跟踪着感兴趣的部分:线条,平面,立体结构…… 人的视觉系统能够精确地理解物体的形状,理解拓扑,而且这些都是 3D 的。人脑看到的不是像素,而是一个 3D 拓扑模型。
眼睛观察的顺序,不是一行一行从上往下把每个“像素”都记下来,做成 6000x4000 像素的图片,而是聚焦在重点上。它可以沿着直线,也可以沿着弧线观察,可以转着圈,也可以跳来跳去的。人脑通过自己的理解能力,控制着眼睛的运动,让它去观察所需要的重点。由于视网膜中央分辨率极高,所以人脑可以得到精度非常高的信息。然而由于不是每个地方都看的那么仔细,所以眼睛采集的信息量可能不大,人脑需要处理的信息也不会很多。
人的视觉系统能理解点,线,面的概念,理解物体的表面是连续的还是有洞,是凹陷的还是凸起的,分得清里和外,远和近,上下左右…… 他能理解物体的表面是什么质地,如果用手去拿会有什么样的反应。他能想象出物体的背面大概是什么样子,他能在头脑中旋转或者扭曲物体的模型。如果物体中间有缺损,他甚至能猜出那位置之前什么样子。
人的视觉系统比摄像头有趣的多。很多人都看过“光学幻觉”(optical illusion)的图片,它们从一个角度揭示了人的视觉系统背后在做什么。比如下图本来是一个静态的图片,可是你会感觉有很多黑点在白线的交叉处闪烁。这个幻觉很经典,被叫做 Herman grid,在神经科学界被广泛研究。稍后我还会提到这个东西。

本来是静态图片,你却感觉它在转。

本来上下两块东西是一样的颜色,可是看起来下面的颜色却要浅一些。如果你用手指挡住中间的高亮部分,就会发现上下两块的颜色其实是一样的。
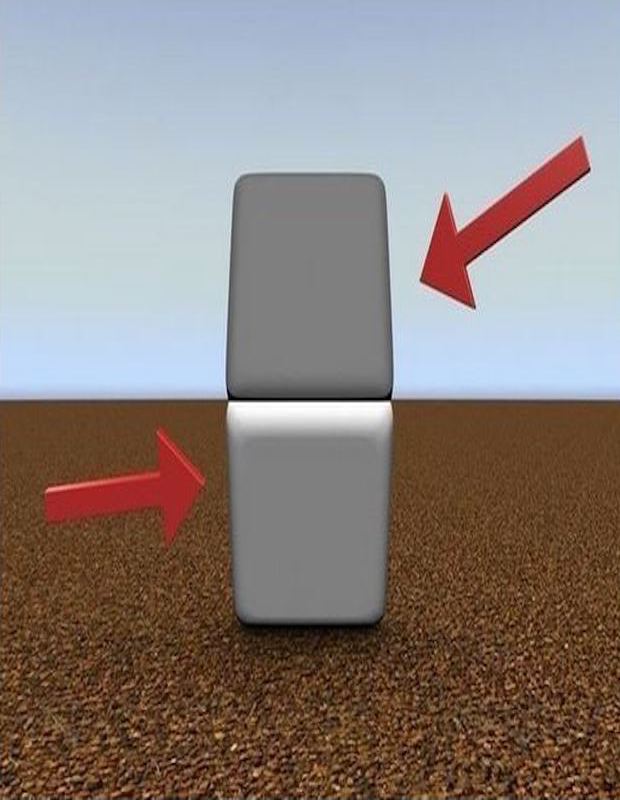
另一个类似的幻觉,是著名的“Abelson 棋盘幻觉”。图中 A 和 B 两个棋盘格子的颜色是一样的,你却觉得 A 是黑色,而 B 是白色。不信的话你可以用软件把这两块格子从图片上切下来,挨在一起对比一下。如果你好奇这是为什么,可以参考这篇文章。

在下图里,你会觉得看见了一个黑色的倒三角形,可是其实它并不存在。

很多的光学幻觉都说明人的视觉系统不是简单的摄像头一样的东西,它具有某些特殊功能。这些特殊功能和机制导致了这些幻觉。这使得人类视觉不同于机器,使得人能够提取出物体的结构信息,而不是只看到像素。
提取物体的拓扑结构特征,这就是为什么人可以理解抽象画,漫画,玩具。虽然世界上没有猫和老鼠长那个样子,一个从来没看过《猫和老鼠》动画片的小孩,却知道这是一只猫和一只老鼠,后面有个房子。你试试让一个没有拿《猫和老鼠》剧照训练过的深度学习模型来识别这幅图?

更加抽象的玩具,人也能识别出它们是哪些人物。头和四肢都变成了方的,居然还是觉得很“像”。你不觉得这很神奇吗?

人脑理解“拓扑”的概念,这使得人能够不受具体像素干扰而正确处理各种物体。对拓扑结构的理解使得人对物体的识别非常准确,甚至可以在信息不完整,模糊,扭曲的情况下工作,在恶劣的天气环境下,有反光,有影子的情况下也能识别物体。
说到反光,你有想过机器要如何才能识别出场景里有一面镜子或者玻璃吗?如果场景中有反光的物体,比如镜子,平静的水面,镀铬的物品,神经网络(CNN)那种依靠像素滤镜训练出来的函数还会有用吗?要知道它们看到的像素,可能有一大片是通过镜面反射形成的,所以无法通过局部的纹理识别出这种情况来。

这是个现实的问题。自动车或者机器人要如何知道前面的路面上有积水或者结冰了?它们要如何知道从水面反射过来的镜像不是真实的物体?比如,它们如何知道下图里路面上的倒影不是真正的树呢?要知道,倒影的像素纹理,跟真实的场景可能是非常相似的。

人是通过对光的理解,各种常识来识别镜子,玻璃,地上的水和冰的存在。一个不理解光和水的性质的机器,它能察觉这些东西的存在吗?靠像素分析能知道这些?要知道,这些东西在某些地方出现,可以是致命的危险。
很有趣的事情,理解光线的反射和折射,似乎已经固化到了每个动物的视觉系统里面。我观察到这一点,是因为我的卧室和客厅之间的橱柜门上有两面大镜子。我的猫在卧室里,能够从镜子里看见我在客厅拿着逗猫绳。他冲过来的时候却不会撞到镜子上面,而是出了卧室门立马转一个角度,冲向我的方向。我每次看到他敏捷的动作都会思考,他是如何知道镜子的存在呢?他是如何知道镜子里的猫就是他自己,而不是另一只猫?

人脑会构造事物的 3D 模型
说了光,再来说影吧。画过素描的人都知道,开头勾勒出的轮廓是没有立体感的,然后你往恰当的位置加一些阴影,就有了立体感。所以动物的视觉系统里存在对影子的分析处理,而且这种功能我们似乎从来没需要学习,生下来就有。“立体视觉”是如此强烈的固化到了我们的头脑里,一旦产生了立体感,你就很难再看见平面的像素。

靠着光和影的组合,人和动物能得到很多信息。比如上图,我们不但看得出这是一个立体的鸡蛋,而且能推断出鸡蛋下面是一个平面,可能是一张桌子,因为有阴影投在了上面。
神经网络知道什么是影子吗?它如何知道影子不是实际存在的物体呢?它能从影子得到有用的信息吗?
神经网络根本不知道影子是什么。早就有人发现,Tesla 基于图像识别的 Autopilot 系统会被阴影所迷惑,以为路面上的树影是一个障碍物,试图避开它,却差点撞上迎面来的车。我在很早的一篇文章已经谈过这个问题。
再来一个关于绘画的话题。学画的初期,很多人都发现画“透视”特别困难。所谓透视就是“近大远小”。本来房子的几堵墙都是长方形,是一样高的,可是你得把远的那一边画短一些,而且相关部分的比例都要画对,就像照片上那样,所以墙就成了梯形的。房顶,窗户等,也全都得做相应的调整。你得这样画,看画的人才会感觉是对的,不然就会感觉哪里不对劲,不真实。
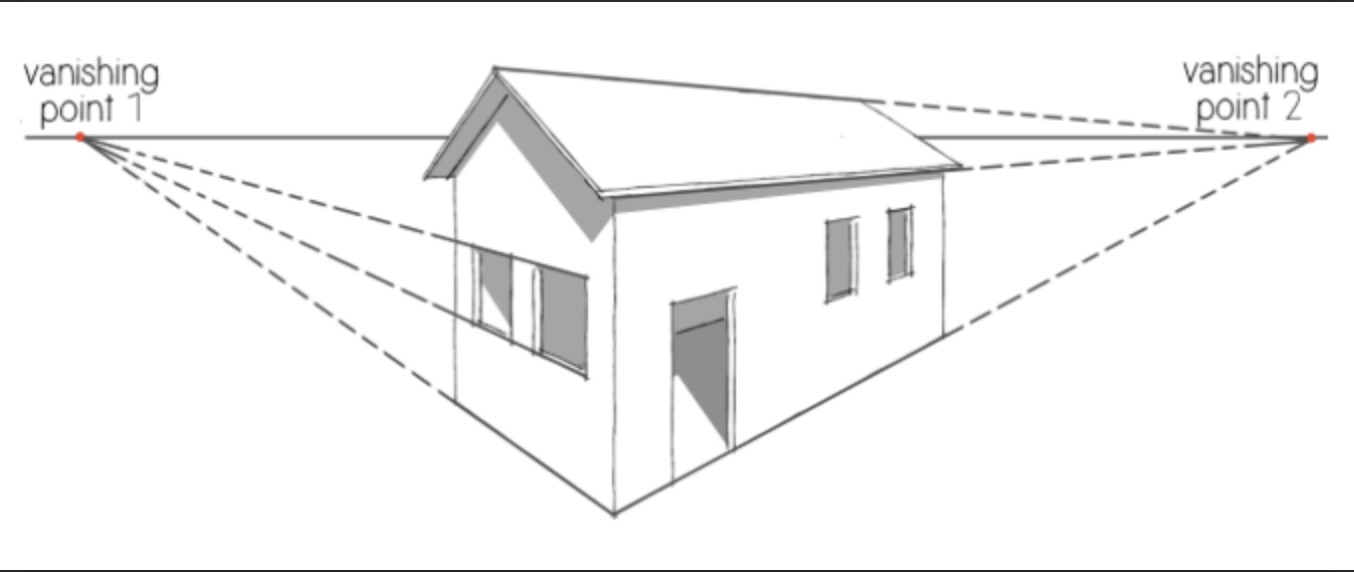
这件事真的很难,大部分人(包括我)一辈子都没学会画透视。虽然拿起笔来量一下,我确实看到远的那一边要短一些,可是我的脑子似乎会“自动纠错”,让我认为它们都是一样长的。所以要是光靠眼睛徒手作画,我会把那些边都画成一样长。我似乎永远学不会画画!
画透视是如此困难的事情,以至于 16 世纪的德国画家丢勒)为此设计了一种专门的设备。

你可能没有想到,这个使得我们学画困难的罪魁祸首,其实是人类视觉系统的一项重要功能,它帮助我们理解身边的环境。虽然眼睛看到的物体是近大远小,可是人脑会自动调整它们在你“头脑里的长度”,所以你知道它们是一样长的。
这也许就是为什么人能从近大远小的光学成像还原出正确的 3D 模型。在你头脑中的模型里面,房子的几堵墙是一样高的,就像它们在现实中的情况一样。有了准确的 3D 模型,人才能正确地控制自己在房子周围的运动。
这种导致我们学画困难的“3D 自动纠错”功能,似乎固化到了每个人,每个高等动物的视觉系统里。我们并不需要学习就有这种能力,它一直都在起作用。反倒是我们要想“关掉”这个功能的时候,需要付出非常多的努力!
为什么人想要画出透视效果那么困难呢?因为一般人画画,都不是在画他们头上那两只眼睛看到的东西,而是在画他们的“心之眼”(mind’s eye)看到的东西——他们头脑中的那个 3D 模型。这个 3D 模型是跟现实“同构”的,模型里房子的墙壁都是一样高的,他们画出来也是一样高的,所以就画错了。只有经过专业训练的画家,才有能力关闭“心之眼”,直接画出眼睛看到的东西。
我猜想,每一种高等动物的视觉系统都有类似的机制,使得它们从光学成像“重构”出与现实同构的 3D 模型。缺乏 3D 建模能力的机器,是无法准确理解看到的物体的。
现在很多自动驾驶车用激光雷达构造 3D 模型,可是相对于人类视觉形成的模型,真是太粗糙了。激光雷达靠主动发射激光,产生一个扫描后的“点云”,分辨率很低,只能形成一个粗糙的 3D 轮廓,无法识别物体,也无法理解它的结构。我们应该好好思考一下,为什么人仅靠被动接收光线就能构造出如此精密的 3D 模型,理解物体的结构,而且能精确地控制自己的动作来操作这些物体。
现在的深度学习模型都是基于像素的,没有抽象能力,不能构造 3D 拓扑模型,甚至连位置关系都分不清楚。缺乏人类视觉系统的这种“结构理解”能力,可能就是为什么深度学习模型需要那么多的数据,那么多的计算,才勉强能得出物体的名字。而小孩子识别物体根本不需要那么多数据和计算,看一两次就知道这东西是什么了。
人脑提取了物体的要素,所以很多信息都可以忽略了,所以人需要处理的数据量,可能比深度学习模型小很多。深度学习领域盲目地强调提高算力,制造出越来越大规模的计算芯片,GPU,TPU…… 可是大家想过人脑到底有多大计算能力吗?它可能并不需要很多计算。
神经网络为什么容易被欺骗
“神经网络”与人类神经系统的关系是是很肤浅的。等你理解了所谓“神经网络”,就会明白它跟神经系统几乎没有一点关系。“神经网络”只是一个误导性质的 marketing 名词,它出现的目的只是为了让外行产生不明觉厉的效果,以为它跟人类神经系统有相似之处,从而对所谓的“人工智能”信以为真。
其实所谓“神经网络”应该被叫做“可求导编程”。说穿了,所谓“神经网络”,“机器学习”,“深度学习”,就是利用微积分,梯度下降法,用大量数据拟合出一个函数,所以它只能做拟合函数能做的那些事情。
用了千万张图片和几个星期的计算,拟合出来的函数也不是那么可靠。人们已经发现用一些办法生成奇怪的图片,能让最先进的深度神经网络输出完全错误的结果。

(图片来源:http://www.evolvingai.org/fooling)
神经网络为什么会有这种缺陷呢?因为它只是拟合了一个“像素=>名字”的函数。这函数碰巧能区分训练集里的图片,却不能抓住物体的结构和本质。它只是像素级别的拟合,所以这里面有很多空子可以钻。
深度神经网络经常因为一些像素,颜色,纹理匹配了物体的一部分,就认为图片上有这个物体。它无法像人类一样理解物体的结构和拓扑关系,所以才会被像素级别的肤浅假象所欺骗。
比如下面两个奇怪的图片,被认为是一个菠萝蜜和一个遥控器,仅仅因为它们中间出现了相似的纹理。
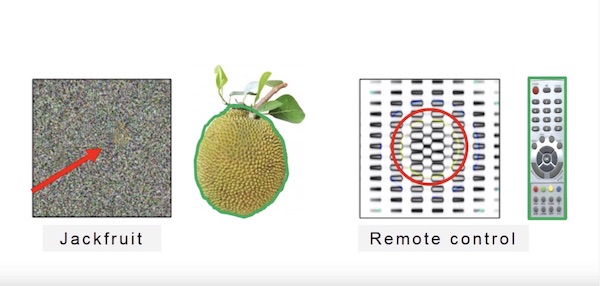
另外,神经网络还无法区分位置关系,所以它会把一些位置错乱的图片也识别成某种物体。比如下面这个,被认为是一张人脸,却没发现五官都错位了。
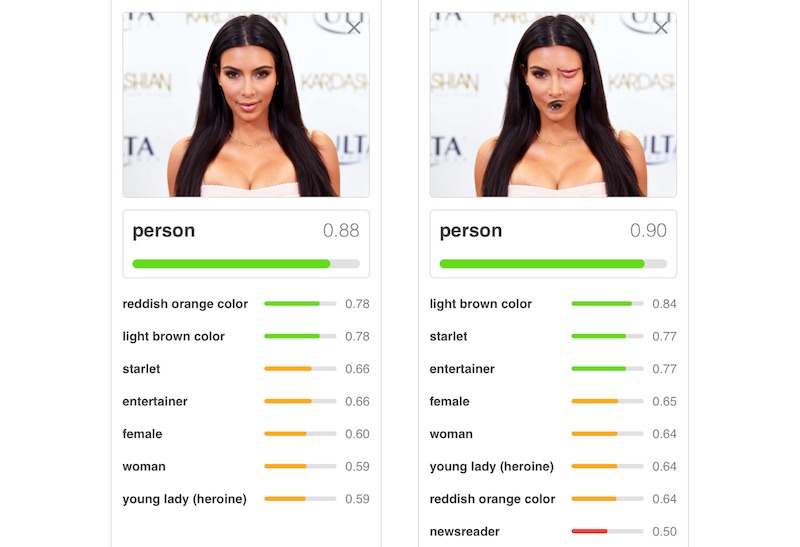
神经网络为什么会犯这种错误呢?因为它的目标只是把训练集里的图片正确分类,提高“识别率”。至于怎么分类,它可以是毫无原则的,它完全不理解物体的结构。它并没有看到“叶子”,“果皮”,“方盒子”,“按钮”,它看到的只是一堆像素纹理。因为训练集里面的图片,出现了类似纹理的都被标记为“菠萝蜜”和“遥控器”,没有出现这纹理的都被标记为其它物品。所以神经网络找到了区分它们的“分界点”,认为看到这样的纹理,就一定是菠萝蜜和遥控器。
我试图从神经网络的本质,从统计学来解释这个问题。神经网络其实是拟合一个函数,试图把标签不同的样本分开。拟合出来的函数试图接近一个“真实分界线”。所谓“真实分界线”,是一个完全不会错的函数,也就是“现实”。
数据量小的时候,函数特别粗糙。数据量大了,就逐渐逼近真实分界线。但不管数据量如何大,它都不可能得到完全准确的“解析解”,不可能正好抓住“现实”。
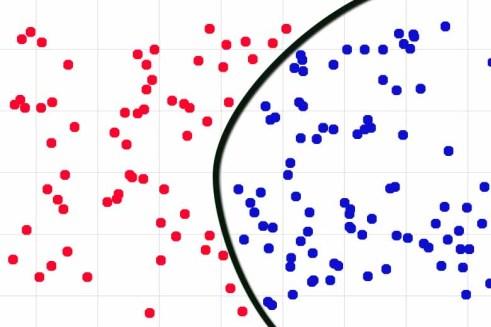
除非现实函数特别简单,运气特别好,否则用数据拟合出来的函数,都会有很多小“缝隙”。以上的像素攻击方法,就是找到真实分界线附近,“缝隙”里面的样本,它们正好让拟合函数出现分类错误。
人的视觉系统是完全不同的,人直接就看到了事物是什么,看到了“解析解”,看到了“现实”,而没有那个用数据逼近的过程,所以除非他累得头脑发麻或者喝了酒,你几乎不可能让他判断错误。
退一步来看,图像识别所谓的“正确分类”都是人定义的。是人给了那些东西名字,是许多人一起标注了训练用的图片。所以这里所谓的“解析解”,“现实”,全都是人定义的。一定是某人看到了某个事物,他理解了它的结构和性质,然后给了它一个名字。所以别的人也可以通过理解同一个事物的结构,来知道它是什么。
神经网络不能看到事物的结构,所以它们也就难以得到精确的分类,所以机器在图像识别方面是几乎不可能超越人类的。现在所谓的“超人类视觉”的深度学习模型,大部分都是欺骗和愚弄大众。使用没有普遍性的数据集,使用不公平的准确率标准来对比,所以才显得机器好像比人还厉害了。这是一个严重的问题,在后面我会详细分析。
神经网络训练很像应试教育
神经网络就像应试教育训练出来的学生,他们的目标函数是“考高分”,为此他们不择手段。等毕业工作遇到现实的问题,他们就傻眼了,发现自己没学会什么东西。因为他们学习的时候只是在训练自己“从 ABCD 里区分出正确答案”。等到现实中没有 ABCD 的时候,他们就不知道怎么办了。
深度学习训练出来的那些“参数”是不可解释的,因为它们存在的目的只是把数据拟合出来,把不同种类的图片分离开,而没有什么意义。AI 人士喜欢给这种“不可解释性”找借口,甚至有人说:“神经网络学到的数据虽然不可解释,但它却出人意料的有效。这些学习得到的模型参数,其实就是知识!”
这些模型真的那么有效吗?那为什么能够被如此离谱的图片所欺骗呢?说“那就是知识”,这说法简直荒谬至极,严重玷污了“知识”这个词的意义。这些“学习”得到的参数根本就不是本质的东西,不是知识,真的就是一堆毫无道理可言的数字,只为了降低“误差”,能够把特征空间的图片区分开来,所以神经网络才能被这样钻空子。
说这些参数是知识,就像在说考试猜答案的技巧是知识一样可笑。“另外几套题的第十题都是 B,所以这套题的第十题也选 B”…… 深度学习拟合函数,就像拿历年高考题和它们的答案来拟合函数一样,想要不上课,不理解科目知识就做出答案来。有些时候它确实可以蒙对答案,但遇到前所未见的题目,或者题目被换了一下顺序,就傻眼了。
人为什么可以不受这种欺骗呢?因为人提取了高级的拓扑结构,不是瞎蒙的,所以人的判断不受像素的影响。因为提取了结构信息,人的观察是具有可解释性的。如果你问一个小孩,为什么你说这是一只猫而不是一只狗呢?她会告诉你:“因为它的耳朵是这样的,它的牙是那样的,它走路的姿势是那样的,它常常磨爪子,它用舌头舔自己……”
做个实验好了,你可以问问你家孩子这是猫还是狗。如果是猫,为什么他们认为这是一只猫而不是一只狗?

神经网络看到一堆像素,很多层处理之后也不知道是什么结构,分不清“眼睛”,“耳朵”和“嘴”,更不要说“走路”之类的动态概念了,所以它也就无法告诉你它认为这是猫的原因了。拟合的函数碰巧把这归成了猫,如果你要追究原因,很可能是肤浅的:图片上有一块像素匹配了图片库里某只猫的毛色纹理。
有一些研究者把深度神经网络的各层参数拆出来,找到它们对应的图片中的像素和纹理,以此来证明神经网络里的参数是有意义的。咋一看好像有点道理,原来“学习”就能得到这么多好像设计过的滤镜啊!可是仔细一看,里面其实没有多少有意义的内容,因为它们学到的参数只是能把那些图片类别分离开。
所以人的视觉系统很可能是跟深度神经网络原理完全不同的,或者只有最低级的部分有相似之处。
“神经网络”与人类神经元的关系是肤浅的
请不要轻易地以为以上指出的问题有解决方案。我提到上面的问题时,有些人会跟我提 Hinton 的 capsule network。很可惜 capsule network 根本就是一个拍脑袋想出来的东西,训练计算量要求异常的大,无法投入实用,也无法验证它的准确性。
为什么 AI 人士总是认为视觉系统的高级功能都能通过“学习”得到呢?非常可能的事情是,人和动物视觉系统的“结构理解”,“3D建模”功能不是学来的,而是早就固化在基因里了。想一想你生下来之后,有任何时候看到世界是平面的,毫无关联的像素吗?
所以我觉得,人和动物生下来就跟现有的机器不一样,结构理解所需的硬件在胚胎里就已经有了,只等发育和激活。人是有学习能力,可是人的学习是建立在结构理解之上,而不是无结构的像素。另外人的“学习”很可能处于比较高的层面,而不是神经元那么“底层”的。人的神经系统里面并没有机器学习那种 back-propagation。
纵使你有再多的数据,再多的计算力,你能超越为期几十亿年的,地球规模的自然进化和选择吗?与其自己去“训练”或者“学习”,不如直接从人身上抄过来!但问题是,我们真的知道人的视觉系统是如何工作的吗?
神经科学家们其实并没有完全搞明白人类视觉系统是如何工作的。就像所有的生物学领域一样,人们的理解仍然是很粗浅的。神经网络与人类视觉系统的关系是肤浅的。每当你质疑神经网络与人类视觉系统的关系,AI 研究者就会抬出 Hubel & Wiesel 在 1959 年拿猫做的那个实验:“有人已经证明了人类视觉系统就是那样工作的!” 如此的自信,不容置疑的样子。
我问你啊,如果我们在 1959 年就已经知道人类视觉系统的工作原理细节,为什么现在还各种模型改来改去,训练来训练去呢?直接模仿过来不就行了?所以这些人的说法是自相矛盾的。
你想过没有,为什么到了 2019 年,AI 人士还拿一个 60 年前的实验来说明问题?这 60 年来就没有新的发现了吗?而且从 H&W 的实验你可以看出来,它只说明了猫的视觉神经有什么样的底层功能(能够做“线检测”),却没有说那就是全部的构造,没说上层的功能都是那样够构造的。
H&W 的实验只发现了最底层的“线检测”,却没有揭示这些底层神经元的信号到了上层是如何组合在一起的。“线检测”是图像处理的基础操作。一个能够识别拓扑结构的动物视觉系统,理所当然应该能做“线检测”,但它应该不止有这种低级功能。
视觉系统应该还有更高级的结构,H&W 的实验并没能回答这个问题,它仍然是一个黑盒子。AI 研究者们却拿着 H&W 的结果大做文章,自信满满的声称已经破解了动物视觉系统的一切奥秘。
那些说“我们已经完全搞明白了人类视觉是如何工作”的 AI 人士,应该来看看这个 2005 年的分析 Herman grid 幻觉现象的幻灯片。这些研究来自 Schiller Lab,MIT 的脑科学和认知科学实验室。通过一系列对 Herman grid 幻觉图案的改动实验,他们发现长久以来(从 1960 年代开始)对产生这种现象的理解是错误的:那些暗点不是来自视网膜的“边沿强化”功能。他们猜想,这是来自大脑的 V1 视觉皮层的 S1 “方向选择”细胞。接着,另一篇 2008 年的 paper 又说,Schiller 的结果是不对的,这种幻觉跟那些线条是直的有关系,因为你如果把那些白线弄弯,幻觉就消失了。然后他们提出了他们自己的,新的“猜想”。

从这种研究的方式我们可以看出,即使是 MIT 这样高级的研究所,对视觉系统的研究还处于“猜”的阶段,把人脑作为黑盒子,拿一些图片来做“行为”级别的实验。他们并没有完全破解视觉系统,看到它的“线路”和“算法”具体如何工作,而是给它一些输入,测试它的输出。这就是“黑盒子”实验法。以至于很多关于人类视觉的理论都不是切实而确定的,很可能是错误的猜想。
脑科学发展到今天也还是如此,AI 领域相对于脑科学的研究方式,又要低一个级别。2019 年了,仍然抬出神经科学家 1959 年的结果来说事。闭门造车,对人家的最新成果一点都不关心。现在的深度神经网络模型基本是瞎蒙出来的。把一堆像素操作叠在一起,然后对大量数据进行“训练”,以为这样就能得到所有的视觉功能。
动物视觉系统里面真有“反向传导”(back-propagation)这东西吗?H&W 的实验里面并没有发现 back-propagation。实际上神经科学家们至今也没有发现神经系统里面有 back-propagation,因为神经元的信号传递机制不能进行“反向”的通信。很多神经科学家的结论是,人脑里面进行 back-propagation 不大可能。
所以神经网络的各种做法恐怕没有受到 H&W 实验的多大启发。只是靠这么一个肤浅的相似之处来显得自己接近了“人类神经系统”。现在的所谓“神经网络”,其实只是一个普通的数学函数的表达式,里面唯一起作用的东西其实是微积分,所谓 back-propagation,就是微积分的求导操作。神经网络的“训练”,就是反复求导数,用梯度下降方法进行误差最小化,拟合一个函数。这一切都跟神经元的工作原理没什么关系,完全就是数学。
为了消除无知带来的困惑,你可以像我一样,自己去了解一下人类神经系统的工作原理。我推荐你看看这个叫《Interactive Biology》的 YouTube 视频系列。你可以从中轻松地理解人类神经系统一些细节:神经元的工作原理,视觉系统的原理,眼睛,视网膜的结构,听觉系统的工作原理,等等。神经学家们对此研究到了如此细节的地步,神经传导信息过程的每一个细节都展示了出来。
AI 研究者并不知道人脑如何工作
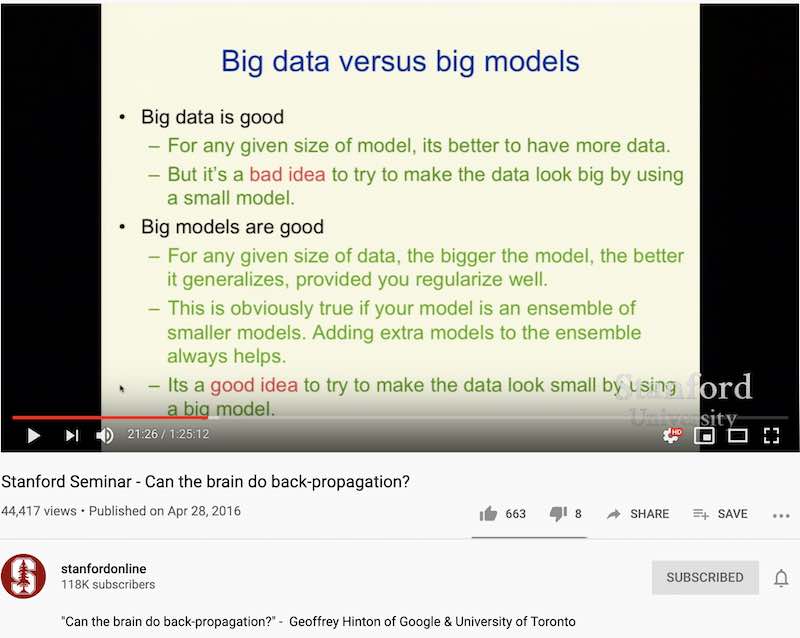
AI 领域真的理解人脑如何工作吗?你可以参考一下这个演讲:”Can the brain do back-propagation?” (人脑能做 back-propagation 吗?)。演讲人是深度学习的鼻祖级人物 Geoffrey Hinton。他和其它两位研究者(Yoshua Bengio 和 Yann LeCun),因为对深度学习做出的贡献,获得了 2018 年的图灵奖。演讲一开头 Hinton 说,神经科学家们说人脑做 back-propagation 是不可能的,然后他开始证明这是可能的,依据神经元的工作原理,back-propagation 如何能用人脑神经元来实现。
是的,如果你有能力让人脑按你的“算法”工作的话,神经元组成的系统也许真能做 back-propagation,可是人脑是你设计的吗?很可惜我们无法改变人脑,而只能去“发现”它到底是如何工作。这不是人脑“能不能”的问题,而是“做不做”的问题。研究人脑是一个科学发现工作,而不是一个工程设计工作。
看了这个演讲,我觉得 AI 人士已经进入了一种“上了天”的状态。他们坚定的认为自己的模型(所谓的“神经网络”)就是终极答案,甚至试图把人脑也塞进这个模型,设想人脑神经元如何能实现他们所谓的“神经网络”。可是他们没有发现,人脑的方式也许比他们的做法巧妙很多,根本跟他们的“神经网络”不一样。
从这个视频我们也可以看出,神经科学界并不支持 AI 领域的说法。AI 领域是自己在那里瞎猜。视频下面有一条评论我很欣赏,他用讽刺的口气说:“Geoff Hinton 确切地知道人脑是如何工作的,因为这是他第 52 次发现人脑工作的新方式。”

AI 人的盲目信仰
AI 人士似乎总是有一种不切实际的“信仰”或者“信念”,他们坚信机器一定可以具有人类一样的智能,总有一天能够在所有方面战胜人类。总是显示出一副“人类没什么了不起”的心态,张口闭口拿“人类”说事,好像他们自己是另外一个物种,已经知道人类的一切能力,有资格评判所有人的智力似的。
我不知道是什么导致了这种“AI 宗教”。有句话说得好:“我所有的自负都来自我的自卑,所有的英雄气概都来自于我内心的软弱,所有的振振有词都因为心中满是怀疑。” 似乎是某种隐藏很深的自卑和怨恨,导致了他们如此的坚定和自负。一定要搞出个超越所有人的机器才善罢甘休,却没发现人类智能的博大精深已经从日常生活的各种不起眼的小事透露出来。
他们似乎看不到世界上有各种各样,五花八门的人类活动,每一种都显示出奇迹般的智能。连端茶倒水这么简单的事情,都包含了机器望尘莫及的智能,更不要说各种体育运动,音乐演奏,各种研究和创造活动了。就连比人类“低级”一点的动物,各种宠物,家畜家禽,飞鸟走兽,甚至昆虫,全都显示出足以让人敬畏的智能。他们对所有这些奇迹般的事物视而不见,不是去欣赏他们的精巧设计和卓越表现,而是坐井观天,念叨着“机器一定会超越人类”。
他们似乎已经像科幻电影似的把机器当成了一个物种,像是保护“弱势群体”一样,要维护机器的“权益”和“尊严”。他们不允许其他人质疑这些机器,不允许你说它们恐怕没法实现人类一样的智能。总之机器在他们心理已经不再是工具,而是活的生命,甚至是比人还高级的生命。
对此你可以参考另一个 Geoffrey Hinton 的采访视频,录制于今年 5 月份的 Google 开发者大会(Google I/O ‘19)。
从这个视频里面我看到了许多 AI 人士盲目信仰和各种没有根据的说法的来源,因为这些说法全都集中而强烈的体现在了 Hinton 的谈话中。他如此的坚信一些没有根据的说法,不容置疑地把它们像真理一样说出来,却没有任何证据。有时候主持人都不得不采用了有点怀疑的语气。
Hinton 在采访中有以下说法:
- “神经网络被设计为像人脑的工作原理。”
- “等神经网络能够跟人对话,我们就能用它来进行教育工作了。”
- “神经网络终究会在所有事情上战胜人类。”
- “我们不都是神经网络吗?” (先后强调了两次)
- “…… 所以神经网络能够实现人类智能的一切功能。这包括感情,意识等。”
- “人们曾经认为生命是一种特殊的力量,现在生物学解释了生命的一切。人们现在仍然认为意识是特殊的,可是神经网络将会说明,意识并没有什么特别。”


他的这些说法都是不准确,不科学,没有根据的。
我发现每当主持人用稍微怀疑的语气问:“这真的可以实现吗?” Hinton 就会回答:“当然能。我们不都是神经网络吗?” 这里有一个严重的问题,那就是他所谓的“神经网络”,其实并不是人脑里面的神经元连成的网络。AI 领域的“神经网络”只是他们自己的数学模型,是他们自己给它起名叫“神经网络”而已。所以他的这种“证明”其实是在玩文字游戏:“因为我们都是神经网络,所以神经网络能够实现一切人类智能,感情,甚至意识本身!”
前面的“神经网络”和后面的“神经网络”完全是两回事。我们是“神经网络”吗?我们的脑子里是有神经元,神经元貌似连成了一个网络,可是它的结构却跟 AI 领域所谓的“神经网络”是两回事,工作原理也非常不一样。Hinton 面对问题作出这样的回答,是非常不科学,不负责任的。
最后关于生命,感情和意识的说法,我也很不认同。虽然生物学解释了生命体的各种构造和原理,可是人们为什么仍然没能从无生命的物质制造出有生命的事物呢?虽然人们懂得那么多生物学,生物化学,有机化学,甚至能合成出各种蛋白质,可是为什么没能把这些东西组装在一起,让它“活”起来呢?这就像你能造出一些机器零件,可是组装起来之后,发现这机器不转。你不觉得是因为少了点什么吗?生物学发展了这么久,我们连一个最简单的,可以说是“活”的东西都没造出来过,你还能说“生命没什么特别的”吗?
这说明生物学家们虽然知道生命体的一些工作原理,却没有从根本上搞明白生命到底是什么。也就是说人们解决了一部分“how”问题(生命体如何工作),却不理解“what”和“why”(生命是什么,为什么会出现生命)。
实际上生物学对生命体如何工作(how)的理解都还远远不够彻底,这就是为什么我们还有那么多病无法医治,甚至连一些小毛病都无法准确的根治,一直拖着,只是不会马上致命而已。“生命是什么”的 what 问题仍然是一个未解之谜,而不像 Hinton 说的,全都搞明白了,没什么特别的。
也许生命就是一种特别的东西呢?也许只有从有生命的事物,才能产生有生命的事物呢?也许生命就是从外星球来的,也许就是由某种更高级的智慧设计出来的呢?这些都是有可能的。真正的科学家应该保持开放的心态,不应该有类似“人定胜天”这样的信仰。我们的一切结论都应该有证据,如果没有我们就不应该说“一定”或者“必然”,说得好像所有秘密全都解开了一样。
对于智能和意识,我也是一样的态度。在我们没有从普通的物质制造出真正的智能和意识之前,不应该妄言理解了关于它们的一切。生命,智能和意识,比有些人想象的要奇妙得多。想要“人造”出这些东西,比 AI 人士的说法要困难许多。
有心人仔细观察一下身边的小孩子,小动物,甚至观察一下自己,就会发现它们的“设计”是如此的精巧,简直不像是随机进化出来的,而是由某个伟大的设计者创造的。46 亿年的时间,真的够进化和自然选择出这样聪明的事物吗?
别误会了,我是不信宗教的。我觉得宗教的圣经都是小人书,都是某些人吓编的。可是如果你坚定的相信人类和动物的这些精巧的结构都是“进化”来的,你坚定的相信它们不是什么更高级的智慧创造出来的,那不也是另外一种宗教吗?你没有证据。没有证据的东西都只是猜想,而不能坚信。
好像扯远了……
总之,深度学习的鼻祖级人物说出这样多信念性质的,没有根据的话,由此可见这个领域有多么混沌。另外你还可以从他的谈话中看出,他所谓的“AI”都是各种相对容易的识别问题(语音识别,图像识别)。他并没有看清楚机器要想达成“理解”有多困难。而“识别”与“理解”的区别,就是我的这篇文章想澄清的问题。
炼丹师的工作方式

设计神经网络的“算法工程师”,“数据科学家”,他们工作性质其实很像“炼丹师”(alchemist)。拿个模型这改改那改改,拿海量的图片来训练,“准确率”提高了,就发 paper。至于为什么效果会好一些,其中揭示了什么原理,模型里的某个节点是用来达到什么效果的,如果没有它会不会其实也行?不知道,不理解。甚至很多 paper 里的结果无法被别的研究者复现,存在作假的可能性。
我很怀疑这样的研究方式能够带来什么质的突破,这不是科学的方法。如果你跟我一样,把神经网络看成是用“可求导编程语言”写出来的代码,那么现在这种设计模型的方法就很像“一百万只猴子敲键盘”,总有一只能敲出“Hello World!”
许多数学家和统计学家都不认同 AI 领域的研究方式,对里面的很多做法表示不解和怀疑。为此斯坦福大学的统计学系还专门开了一堂课 Stats 385,专门讨论这个问题。课堂上请来了一些老一辈的数学家,一起来分析深度学习模型里面的各种操作是用来达到什么目的。有一些操作很容易理解,可是另外一些没人知道是怎么回事,这些数学家都看不明白,连设计这些模型的炼丹师们自己都不明白。
“超人类准确率”的迷雾
我发现神经网络在测试数据的可靠性,准确率的计算方法上,都有严重的问题。
神经网络进行图像识别,所谓“准确率”并不是通过实际数据测出来的,而是早就存在那里的,专用的测试数据,比如 ImageNet。反反复复都是那些,所以实际的准确率和识别效果值得怀疑。数据全都是网络上的照片,但网络上数据肯定是不全面的,拍照的角度和光线都无法概括现实的多样性。而且不管是训练还是测试的数据,他们选择的都是在理想环境下的照片,没有考虑各种自然现象:反光,折射,阴影等。
比如下图就是图像识别常用的 ImageNet 和其它几个数据集的一小部分。你可以看到它们几乎全都是光线充足情况下拍的照片,训练和测试用的都是这样的照片,所以遇到现实的场景,准确率很可能就没有 paper 上那么高了。

如此衡量“准确率”,有点像你做个编译器,却只针对 benchmark 进行优化跑分。一旦遇到实际的代码,别人可能就发现性能不行。但神经网络训练需要的硬件等条件比较昂贵,一般人可能也很少有机会进行完整的模型训练和实际的测试,所以大家只有任凭业内人士说“超人类准确率”,却无法验证它的实际效果。
蹊跷的“top-5 准确率”
不但测试数据的“通用性”值得怀疑,所谓“准确率”的计算标准也来的蹊跷。AI 领域向公众宣扬神经网络准确率的时候,总喜欢暗地里使用所谓“top-5 准确率”,也就是说每张图片给 5 次机会分类,只要其中一个对了就算正确,然后计算准确率。依据 top-5 准确率,他们得出的结论是,某些神经网络模型已经“超越了人类”。

如果他们提到“top-5”还算好的了,大部分时候他们只说“准确率”,而不提“top-5”几个字。在跟人比较的时候,总是说“超越了人类”,而绝口不提“top-5”,不解释是按照什么标准。我为什么对 top-5 有如此强烈的异议呢?现在我来解释一下。
具体一点,“top-5”是什么意思呢?也就是说对于一张图片,你可以给出 5 个可能的分类,只要其中一个对了就算分类正确。比如图片上本来是汽车,我看到图片,说:
- “那是苹果?”
- “哦不对,是杯子?”
- “还是不对,那是马?”
- “还是不对,所以是手机?”
- “居然还是不对,那我最后猜它是汽车!”
五次机会,我说出 5 个风马不及的词,其中一个对了,所以算我分类正确。荒谬吧?这样继续,给很多图片分类,然后统计你的“正确率”。
为什么要给 5 次机会呢?按照 ImageNet 比赛([ILSVRC)的官方说法,是因为人经常用不同的词来描述同一个事物,比如 forest 和 woods 都可以描述一片树林。所以给 5 次机会,免得因为分类成了另外的同义词而被认为是分类错误。

看似合理?然而这却是完全错误的标准。这使得神经网络可以给出像上面那样风马不及的 5 个词(苹果,杯子,马,手机,汽车),却仍然被认为识别正确!
要用 top-5,至少你给出的 5 个类别应该是近义词才算合理吧?可是 ILSVRC 并没有要求给出的 5 个类别是近义词。不管你给出的其他四个分类有多离谱,只要你有一个对了就算分类正确。所以 top-5 准确率总是比 top-1 高很多。高多少呢?比如 ResNet-50 的 top-1 准确率只有 77.1%,而 top-5 准确率却有 93.3%。Top-1 准确率只能算“勉强能用”,换成 top-5 之后,忽然就可以宣称“超越人类”了。
可能很多人都没意识到,这种比较方法对人是不公平的。人要是见过那个物体,几乎总是一次就能做对,根本不需要 5 次机会。使用“top-5 准确率”,就像考试的时候给差等生和优等生各自 5 次机会来做对题目。当然,这样你就分不清谁是差等生,谁是优等生了。“top-5 准确率”大大的模糊了好与坏之间的界线,最后看起来都差不多了,甚至差等生显得比优等生还要好。
具体一点。假设一个人识别那些图片的时候,他的 top-5 错误率是 5.1% (就像他们给出的数字那样),那么他的 top-1 错误率大概也是 5.1%。因为人要是一次机会做不对,那他可能根本就没见过图片上的物体。如果他一次做不对,你给他 5 次机会,他也做不对,因为他根本就不知道那东西叫什么名字。
现在某个神经网络的 top-5 错误率是 4.94%,它的 top-1 错误率是 20% 以上。你却只根据 top-5 得出结论,说神经网络超越了人类。是不是很荒谬?

Top-5 还有另外一个不公平的地方:测试的时候,机器知道所有的“标签集合”(1000 个单词的样子),而人类不知道这个集合里面有哪些单词,或者看了也记不住。因为神经网络是用带有标签的数据集训练出来的,所以神经网络不可能输出这个“标签集合”以外的单词。而人看到一个东西,他有多很多的单词可以选择,所以他的“人类标签集合”可以很大,比如可能是 1 万个单词。如果人不知道数据集的标签集合总共有哪些单词,那么他说出来的单词很可能意思是对的,却匹配不上图片的“正确标签”。机器选择标签的范围很窄,而人选择的范围大很多,所以人恰好选对那个词的机会就更小。所以这不但是一个没道理的文字游戏,而且是一个不公平的文字游戏。
退一万步讲,就算你可以用 top-5,像这种 4.94% 与 5.1% 的差别,也应该是忽略不计的。因为实验都是有误差,有随机性的,根据测试数据的不同也有差异,像这样的实验,0.2% 的差别根本不能说明问题。如果你仔细观察各个文献列出来识别率,就会发现它们列出的数字都不大一样。同样的模型,准确率差距可以有 3% 以上。但他们拿神经网络跟人比,却总是拿神经网络最好的那个数,跟人死扣那百分之零点几的“优势”,然后欢天喜地宣称已经“超人类”了。
而且他们真的拿人做过公平的实验吗?为什么从来没有发布过“神经网络 vs 人类 top-1 对比结果”呢?5.1% 的“人类 top-5 准确率”数字是哪里来的呢?哪些人参加了这个测试,他们都是什么人?我唯一看到对人类表现的描述,是在 Andrej Karpathy 的主页上。他拿 ImageNet 测试了自己的识别准确率,发现好多东西根本没见过,不认识,所以他又看 ImageNet 的图片“训练”自己,再次进行测试,结果准确率大大提高。
就那么一个人得出的“准确率”,就能代表全人类吗?而且你们知道 Andrej Karpathy 是谁吧。他是李飞飞的学生,目前是 Tesla 的 AI 主管,而李飞飞是 ImageNet 的发起者和创造者。让一个“内幕人士”拿自己来测试,这不像是公正和科学的实验方法。你见过有医学家,心理学家拿自己做个实验,就发表结果的吗?第一,人数太少,至少应该有几十个智商正常的人来做这个,然后数据平均一下吧?第二,这个人是个内幕人士,他的表现恐怕不具有客观性。
别误会了,我并不否认 Andrej Karpathy 是个很聪明,说话挺耿直的人。我很欣赏他讲的斯坦福 cs231n 课程,通过他的讲述我第一次明白了神经网络到底是什么,明白了 back-propagation 到底如何工作。我也感谢李飞飞准备了这门课,并且把它无私地放在网上。但是这么大一个领域,这么多人,要提出“超越了人类视觉”这么大一个口号,居然只有研究者自己一个人挺身而出做了实验,你不觉得这有点不负责任吗?
AI 领域对神经网络训练进行各种优化,甚至专门针对 top-5 进行优化,把机器的每一点性能每一点精度都想榨干了去,对于如何让人准确显示自己的识别能力,却漫不经心,没有组织过可靠的实验,准确率数字都不知道是怎么来的,简直可以说是“谣言证据”(anecdotal evidence)。对比一下生物,神经科学,医学,这些领域是如何拿人做实验,如何向大家汇报结果,AI 领域的做法像是科学的吗?
这就是“AI 图像识别超越人类”这种说法来的来源。AI 业界所谓“超人类的识别率”,“90+% 的准确率”,全都是用“top-5 准确率”为标准的,而且用来比较的人类识别率的数字没有可靠的来源。等你用“top-1 准确率”来衡量它们,使用客观公正抽选的人类实验者的时候,恐怕就会发现机器的准确率远远不如人类。
我们再来分析一下 top-5 的官方说法吧,说是为了解决“近义词标签问题”。其实要解决近义词的问题很简单。在进行测试的时候,对于机器的输出,你可以拿一个近义词词典来查找输出的类别。比如,要是输出分类是 woods,而正确分类是 forest,根据近义词词典 woods 和 forest 是近义词,那么算分类正确。如果输出是不同的词,近义词词典也无法把它们关联在一起,那么就算分类错误。
对于人类,判断是否准确识别的方式应该更加灵活一些。要判断人是否识别正确,最好的办法应该有一个公正的人类裁判,实验者给出对图片的描述之后,裁判根据他说出来的单词或者短语,或者更长的描述,来判断他是否识别了图片。毕竟我们想知道的是他是否真的知道图片上是什么,而不是他是否说出了图片的“正确标签”。
另外,图片集的标注也是一个问题。我觉得图片集的标注本来就不该有模棱两可的情况。同一个或者相近的物体,应该只有一个标准的标注词。这样机器就不可能输出错误的近义词,也就没必要用 top-5 识别率了。这样我们就只需要对人类的识别率采用近义词典或者人类裁判。
神经网络的 top-1 识别率真的是因为像 ILSVRC 说的那样,可能会输出“近义词”才那么低吗?你们真的看过神经网络的输出,当它 top-5 正确而 top-1 却错误的时候,其它四个真的是相关的标签吗?我不觉得是这种情况导致了 top-1 识别率比 top-5 低,而是因为 top-5 放过了很多根本就是错误的分类。
就那么随便一说,没有依据,就把准确率的标准设置为 top-5,而 top-5 却又不是解决近义词问题的合理答案。任何一个学过基础编程的学生都应该知道如何解决近义词的问题。AI 领域这么多的高水平程序员,居然一致使用了 top-5。
这么基础而重要的问题,AI 业界的解决方案如此幼稚,却被全世界研究者广泛接受。你们不觉得蹊跷吗?我觉得他们有自己的目的:top-5 使得神经网络的准确率显得很高,只有使用这个标准,神经网络才会看起来“超越了人类”。
尴尬的 top-1 准确率
我们来看看 top-1 准确率吧。业界最先进的模型之一 ResNet-152 的 top-1 准确率只有 77.6%。2017 年的 ImageNet 分类冠军 SENet-154,top-1 准确率也只有 81.32%。当然这也没有考虑过任何实际的光线,阴影和扭曲问题,只是拿标准的,理想情况的 ImageNet “测试图片”来进行。遇到实际的情况,准确率肯定会更低。
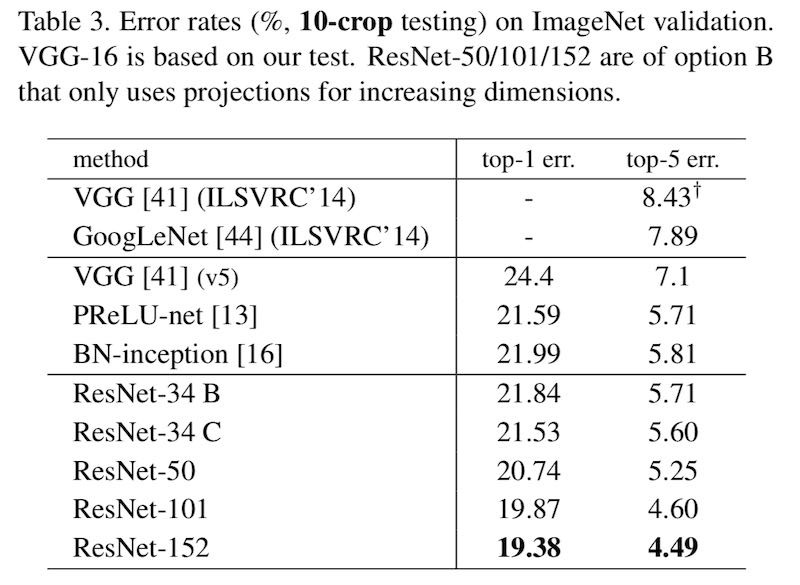
神经网络要想提高 top-1 准确率已经非常困难了,都在 80% 左右徘徊。有些算法工程师告诉我,识别率好像已经到了瓶颈,扩大模型的规模才能提高一点点。可是更大的模型具有更多的参数,也就需要更大规模的计算能力来训练。比如 SENet-154 尺寸是 ResNet-152 的 1.7 倍,ResNet-152 尺寸又是 ResNet-50 的 2.4 倍,top-1 准确率才提高一点点。
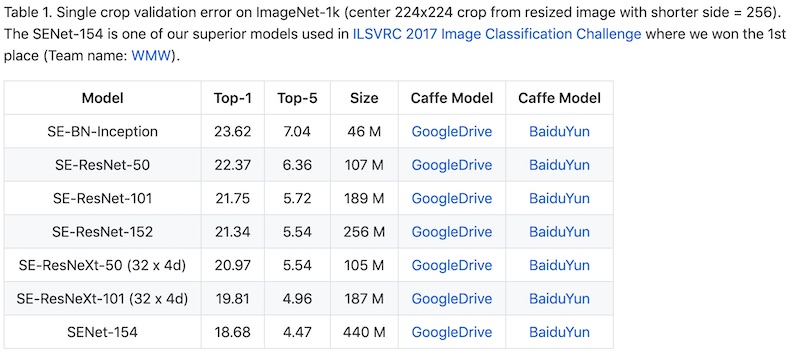
我还有一个有趣的发现。如果你算一下 ResNet-50 和 ResNet-152 的差距,就会发现 ResNet-152 虽然模型大小是 ResNet-50 的 2.4 倍,它的 top-1 错误率绝对值却只降低了 1.03%。从 22.37% 降低到 21.34%,相对降低了 (22.37-21.24)/22.37 = 4.6%,很少。可是如果你看它的 top-5 错误率,就会觉得它好了不少,因为它从 6.36% 降低到了 5.54%,虽然绝对值只少了 0.82%,比 top-1 错误率的改进还小,可是相对值却降低了 (6.36-5.54)/6.36 = 12.9%,就显得改进了挺多。
这也许就是为什么 AI 业界用 top-5 的第二个原因。因为它的错误率基数很小,所以你减小一点点,相对的“改进”就显得很多了。而如果你看 top-1 准确率,就会觉得几乎没有变化。模型虽然大了几倍,计算量大了那么多,准确率却几乎没有变。
所以你又意识到,Hinton 在他的演讲中说到的“同样的数据,大的模型更好”,很可能并不是那样的。
模型里面有这么多的参数,说明我们并没有抓住问题的本质。科学家都知道,当我们需要越来越大,越来越复杂的模型才能概括自然规律的时候,那说明这个模型很可能是错的。这就是为什么爱因斯坦的相对论那么可贵,因为它简单地解释了许多复杂的模型都无法概括的自然规律。
AI 业界的诚信问题和自动驾驶的闹剧
准确率不够高其实问题不大,只要你承认它的局限性,把它用到能用的地方就行了。可是最严重的问题是人的诚信,AI 人士总是夸大图像识别的效果,把它推向超出自己能力的应用。AI 业界从来没有向公众说清楚他们所谓的“超人类识别率”是基于什么标准,反而在各种媒体宣称“AI 已经超越了人类视觉”。这完全是在欺骗和误导公众。上面 Geoffrey Hinton 的采访视频中,主持人也提到“神经网络视觉超越了人类”,这位深度学习的先驱者对此没有任何说明,而是欣然接受,继续自豪地夸夸其谈。
你可以给自动驾驶车 5 次机会来判断前面出现的是什么物体吗?你有几条命可以给它试验呢?Tesla 的 Autopilot 系统可能 top-5 正确率很高吧:“那是个白板…… 哦不对,那是辆卡车!” “那是块面包…… 哦不对,那是高速公路的隔离带!”
我不是开玩笑,你点击上面的“卡车”和“隔离带”两个链接,它们指向的是 Tesla Autopilot 引起的两次致命车祸。第一次车祸,Autopilot 把卡车识别为白板,直接从侧面撞上去,导致车主立即死亡。另一次,它开出车道,没能识别出高速公路中间的隔离带,完全没有减速,反而加速撞上去,导致车主死亡,并且着火爆炸。

神经网络能把卡车识别为白板还算“top-5 分类正确”,Autopilot 根本没有视觉理解能力,这就是为什么会引起这样可怕的事故。

你可以在这里看到一个 Autopilot 导致的事故列表。
出了挺多人命,可是“自动驾驶”的研究仍然在混沌中进行。2018 年 3 月,Uber 的自动驾驶车在亚利桑那州撞死一名推自行车过马路的女性。事故发生时的车载录像)已经被公布到了网上。
报告显示,Uber 的自动驾驶系统在出事前 6 秒钟检测到了这位女士,起初把她分类为“不明物体”,然后分类为“汽车”,最后分类为“自行车”,完全没有刹车,以每小时 40 英里的速度直接撞了上去…… 【新闻链接】
在此之前,Uber 被加州政府吊销了自动驾驶实验执照,后来他们转向了亚利桑那州,因为亚利桑那州长热情地给放宽政策,“拥抱高科技创新”。结果呢,搞出人命来了。美国人看到 Uber 自动车撞死人,都在评论说,要实验自动驾驶车就去亚利桑那州吧,因为那里的人命不值钱,撞死不用负责!
据 2018 年 12 月消息,Uber 想要重新开始自动驾驶实验,这次是在宾夕法尼亚州的匹兹堡。他们想要在匹兹堡的闹市区进行自动驾驶实验,因为那里有狭窄的街道,列车铁轨,许多的行人…… 我觉得要是他们真去那里实验,可能有更好的戏看了。
自动驾驶领域使用的视觉技术是根本不可靠的,给其它驾驶者和行人造成生命威胁,各个自动驾驶公司却吵着想让政府交通部门给他们大开绿灯。某些公司被美国政府拒绝批准牌照之后大吵大闹,骂政府监管部门不懂他们的“高科技”,太保守,跟不上时代。有的公司更是异想天开,想要政府批准他们的自动车上不安装方向盘,油门和刹车,号称自己的车已经不需要人类驾驶员,甚至说“只有完全去掉了人类的控制,自动车才能安全运行。”

一出出的闹剧上演,演得好像自动驾驶就快实现了,大家都在拼命抢夺这个市场似的,催促政府放宽政策。很是有些我们当年大炼钢铁,超英赶美的架势。这些公司就跟小孩子耍脾气要买玩具一样,全都吵着要爸妈让他玩自动驾驶,各种蛮横要求,马上给我,不然你就是不懂高科技,你就是“反智”,“反 AI”,你就是阻碍历史进步!给监管机构扣各种帽子,却完全不理解里面的难度,伦理和责任。玩死了人,却又抬出各种借口,不想负责任。
自动驾驶领域最著名,最不负责任的人,当属 Tesla 的 Elon Musk 先生了。他不但总是对 Tesla 的 Autopilot 进行夸大的宣传,让人误解它的能力而导致车祸,死了人之后还要在网上发话扭曲人们的逻辑和伦理,让明眼人恶心。Tesla 公司总是抓住“车主开车不专心”等各种借口,逃脱对事故的责任。
几乎每次 Tesla Autopilot 判断错误撞死了人,Elon Musk 都会出来说:“自动驾驶的事故率还是远远低于人类驾驶员!” 很多书呆子极客会听信他的“事故率”,为他的所谓“高科技”欢呼而忽略死者,可是他们不明白,这些大范围的统计数字对于事故责任分析,对于伦理是没用的。
他的说法就相当于在说:“我活了这么久,为这么多客户服务,没杀过其中任何一个,我杀人的概率非常低,低于全国的谋杀犯罪率,所以我现在杀了你不用负责。” 先不说 Autopilot 的事故率是否真的那么低。即使它事故率是很低,难道弄死了人就可以不负责,甚至不受谴责吗?
到底 Tesla 有没有责任,我们可以使用因果关系的“反事实分析”(counterfactual):如果驾驶员没有使用 Autopilot 而是自己开车,这次事故还会不会发生?如果不会发生,那么我们得到因果关系:Autopilot 导致了事故。不管其他人用 Autopilot 有没有出事故,事故占多大比例,面对这里的因果关系都是无关紧要的。因果关系==责任。
如果是 Autopilot 导致了事故,即使总共只发生了一次事故,都该它的设计者 Tesla 公司负责。很多人都是混淆了“责任”,“伦理”和“事故率”,所以才会继续支持 Elon Musk 和 Tesla 的欺诈行为。很多人总是以为“自动驾驶可能会降低全国的车祸率”,所以我们应该支持这些研究,而不明白事故率跟责任和伦理是两码事。
如果拿事故率说事,航空业的事故率远远低于汽车业了吧?可是为什么全世界几年才一次空难,却每一次都带来那么多的恐慌,进行那么严格的调查,追究责任呢?就是因为我之前分析的,责任和事故率完全是两回事。只要有死伤,肯定有人要被调查,被追究,要负责的。只要人为导致了事故,都是不会被放过的,不管他的总体“事故率”如何低都一样要被惩罚。
Autopilot 的事故率真的低吗?你可以自己研究一下。如果你算对了数学,恐怕它的事故率并不低。举一个例子,普通人只计算了事故的数目与 Autopilot 导航的总里程的比例,却忽视了那些由于驾驶员及时接管而避免了的事故的数目。另外 Tesla 属于比较贵的车,买车的人属于对自己比较负责的人,所以事故率不应该跟所有车的事故率比,而应该跟没有安装自动驾驶技术的奔驰,保时捷一类的车的事故率对比。
每一次 Autopilot 相关的事故,Tesla 公司都会在事后散布新闻说是驾驶者开车不认真,手没有在方向盘上,不是 Autopilot 的责任。他们是否认真在开车,人死了无所对证,但这些全都成为了 Tesla 公司推脱责任的借口。
Tesla 对 Autopilot 功能的不实宣传,导致了很多人产生盲目的信任,随即导致了放松警惕,这一切都是由 Tesla 而起的。启动 Autopilot 的时候签个生死状,说手必须一直放在方向盘上准备随时接管,否则后果自负。到头来一旦找出你没有认真开车的迹象,就把责任推得一干二净。
所以 Tesla 不但视觉技术不行,而且人品和诚信都很成问题。我还没有见过一个汽车公司如此急于推脱责任的,一般都是积极配合调查,勇于承担责任,及时整改,这样才可能得到公众的信任。
虽然 Tesla 和 Uber 是应该被谴责的,但这里面的视觉问题不只是这两家公司的问题,整个自动驾驶的领域都建立在虚浮的基础上。我们应该清楚地认识到,现有的所谓 AI 根本没有像人类一样的视觉理解能力,它们只是非常粗糙的图像识别,识别率还远远达不到人类的水平,所以根本就不可能实现自动驾驶。
什么 L1~L4 的自动驾驶分级,都是瞎扯。根本没法实现的东西,分了级又有什么用呢?只是拿给这些公司用来忽悠大家的口号,外加推脱责任的借口而已。出事故前拿来做宣传:“我们已经实现 L2 自动驾驶,目前在研究 L3 自动驾驶,成功之后我们向 L4 进军!” 出事故后拿来推脱责任:“我们只是 L2 自动驾驶,所以这次事故是理所当然,不可避免的!”
如果没有视觉理解,依赖于图像识别技术的“自动驾驶车”,是不可能在复杂的情况下做出正确操作,保障人们安全的。机器人等一系列技术,也只能停留在固定场景,精确定位的“工业机器人”阶段,而不能在复杂的自然环境中行动。
我认识一些工业机器人的研究者。他们告诉我,深度神经网络那些识别算法太不精确了,根本没法用于准确性要求很高的应用。工业机器人控制不精确是完全不可接受的,所以他们都不用深度神经网络来控制机器人。
识别技术还是有意义的
要实现真正的语言理解和视觉理解是非常困难的,可以说是毫无头绪。真正的 AI 其实没有起步,很多 AI 人士忙着忽悠和布道,根本没人关心其中的本质,又何谈实现呢?除非真正有人关心到问题所在,去研究本质的问题,否则实现真的理解能力就只是空中楼阁。我只是提醒大家不要盲目乐观,不要被忽悠了。
我并不是一味否定识别技术,我只是反对把识别夸大为“理解”,把它等同于“智能”,进而进行不实宣传,用于超出它能力的领域。诚实地使用识别技术还是有用的,而且蛮有趣。我们可以用这些东西来做一些很有用的工具,辅助我们进行一些事情。从公安侦查,图片搜索,内容推荐,商业金融数据分析,反洗钱,医学图像分析,疾病预测,网络攻击监测,各种娱乐性质的 app…… 它确实可以给我们带来挺多好处,实现我们以前做不到的一些事情。
另外虽然我认为各公司都在对他们的“AI 对话系统”进行夸大和忽悠,可是如果我们放弃“真正的对话”,坦诚地承认它们并不是真正的在对话,并没有智能,那它们确实可以给人带来一些便利。现有的所谓对话系统,比如 Siri,Alexa,基本可以被看作是语音控制的命令行工具。你说一句话,机器就挑出其中的关键字,执行一条命令。这虽然不是有意义的对话,却可以拿来提供一些方便。特别是在开车不方便看屏幕的时候,语音控制“下一首歌”,“空调风量调小一点”,“导航到最近的加油站”之类的命令,还是有用的。早上醒来眼睛都是模糊的,说一声:“Hey Siri,今天会不会下雨?” 还是比拿起手机点来点去舒服一些。
但不要忘记,识别技术不是真的智能,它没有理解能力,不能用在自动驾驶,自动客服,送外卖,厨师,发型师,运动员等需要真正“视觉理解”或者“语言理解”能力的领域,更不能期望它们取代教师,程序员,科学家等需要高级知识的工作。机器也没有感情和创造力,不能取代艺术家,作家,电影导演。所有跟你说机器也能有“感情”或者“创造力”的都是忽悠,就像现在的对话系统一样,只是让人以为它们有那些功能,而其实根本就没有。
你也许会发现,机器学习很适合用来做那些不直观,人看不透,或者看起来很累的领域,比如各种数据分析。实际上那些就是统计学一直以来想解决的问题。可是视觉这种人类和高等动物的日常功能,机器的确非常难以超越。如果机器学习领域放弃对“人类级别智能”的盲目追求,停止拿“超人类视觉”一类的幌子来愚弄大众,各种夸大,那么他们应该能在很多方向做出积极的贡献。